


IBM開発のスーパーコンピューター「ディープブルー」が当時のチェス世界チャンピオンに勝利したのはちょうど20年前の1997年。それに続いて開発されたIBMの人工知能「ワトソン」は2011年、人間相手のクイズ対決を制しています。
そして2017年5月、囲碁AI「AlphaGo」がフューチャー碁サミットにて人類最強とまで謳われた棋士を下しました。
この20年の間、人工知能はゲームという舞台で人間に対する優越性をまざまざと見せつけてきたのです。ゲームをプレイすることを覚えた人工知能は、これからどこへ向かうのでしょうか?
人工知能とゲームをめぐる歴史の中で、AlphaGoの登場は大きなブレークスルーの一つでした。
囲碁はチェスよりもさらに複雑なゲームです。局面の数はチェスよりはるかに多く、打つ手を決めるには高度の創造性を要するので、碁を打つ人工知能を開発するためには人間の思考を高いレベルで再現する必要があったのです。
AlphaGoはディープラーニングという技術でそれを実現しました。そしてこの技術の登場こそ、こんにち誰もが人工知能に注目するようになったきっかけなのです。
そのような華々しい記録を残したAlphaGOですが、開発元のDeepmind社はすでに囲碁からの引退を決定。
Deepmind社が今後の目標として掲げたのは、世界的に大ヒットしたコンピューターゲームである『Starcraft II』をクリアできる人工知能を作ることです。
完全情報ゲームと不完全情報ゲーム
Deepmind社がコンピューターゲームに注目した理由はなんなのでしょう?これを読み解くには、ゲームというものの性質に着目する必要があります。
ゲームは「完全情報ゲーム」と「不完全情報ゲーム」の2種類に大別できます。
完全情報ゲームとは簡単に言えば、プレイヤーがそれまでゲーム中に起きた全ての出来事を知ることができるゲームです。
例えばチェスはこの定義に当てはまります。チェスプレーヤーは両者ともつねに盤全体を見ることができるので、自分の打った手に相手がどう対応したか、また盤全体の状態を判断材料として使い、相手の意図をある程度読んだ上で意思決定が可能となります。

不完全情報ゲームとはこれに当てはまらないゲームで、一例としてポーカーが挙げられます。
ポーカーの目的は手持ちのカードを捨てたり新しいカードを引いたりを決められた回数繰り返し、相手よりも強力な(=揃う確率が低い)カードの組み合わせを作ることです。
しかしポーカーでは他プレーヤーの持っているカードや捨てたカードを見ることができません。そのことを利用して、弱い組み合わせでも強気に振る舞い相手のドロップ(負けたときの損を抑えるため賭け金がつり上がる前にゲームを降りること)を誘うという「ハッタリ」を駆使する余地も生まれます。
自分のカードの組み合わせは相手より強いのか、相手はどんな組み合わせを狙っているか、そもそも相手の動きはハッタリではないのか、そのどれも確実にはわからない――不完全情報ゲームの枠組みの中では活用できる判断材料が限られるので、完全情報ゲームよりも意思決定が難しくなるのです。
また場の全体像を知る方法がなく、確実な見通しを欠いた状態で意思決定を行わなければならない不完全情報ゲームは、完全情報ゲームよりも現実の状況に近いといえるでしょう。
不完全情報ゲームに対応できる人工知能を創り上げることは、チェスや囲碁よりはるかに不確実性が高い現実世界の問題解決に対応できる高度な人工知能、ひいては汎用人工知能の開発へと至るための重要なステップなのです。
Starcraft IIと人工知能
Starcraft IIはリアルタイムストラテジー(RTS)と呼ばれるジャンルのゲームです。RTSではプレーヤーは戦場となるフィールドを上から見下ろし、駒(ユニット)を動かして相手を攻めていきます。
特徴的なのは、囲碁や将棋のように自分の番、相手の番とユニットを動かすタイミングが区切られていない点です。なので両者のユニットたちは常に動いていて、時々刻々と状況が変わっていくという、かなり忙しいゲームとなります。
また、Starcraft IIは不完全情報ゲームに分類されます。
このゲームでは基本的に自分のユニットの近くにいる相手ユニットしか見ることができないので、必然的に相手ユニット全ての動きを常に把握するということは不可能なのです。
そしてStarcraft IIでは、常に状況が変化するというRTSの性質上、意思決定に時間的制約が存在します。不確定要素が存在する状況での意思決定を限られた時間内に行わなければならないStarcraft IIは、かなり現実世界の状況に近いゲームなのです。
DeepMindが人工知能研究の部隊を囲碁からStarcraft IIに移したことは、現実の問題によりよく対応できる人工知能というブレークスルーにつながる意欲的なステップだと言えるでしょう。
協力する人工知能
Starcraft IIをクリアできる人工知能を研究するもうひとつの意義は、協調して行動できるAIを作り出すことです。
Starcraft IIでは、性質の違う複数のユニットの集団を操作し、敵を倒していくことが求められます。人工知能がStarcraft IIをクリアしようとすれば、全体の目的と状況との兼ね合いから判断し、個々のユニットのチームワークを計算に入れた戦法を学習できなければならないのです。
集団行動を学習する人工知能は、人工知能が制御する個体ごとの一番得な行動はなにかという情報を共有し、それをもとに「全体としての得の総和」を計算して各個体の行動を変えていくものといえます。
アリのふるまいを例にとってみましょう。
巣を出た一匹のアリが北に向かい、大量のエサを見つけたとします。この時アリは一匹で運べるだけのエサを取り、道にフェロモンを残しながら巣に戻っていきます。一匹のアリがエサを見つけることは個体にとっての得であり、集団にとっても得になるできごとです。
エサを見つけたアリのフェロモンは匂いを発し、巣の仲間はそれをたどって北に歩いて行きます。これは「得になるものがある」という情報の共有であるといえます。
一匹目のアリのつけたフェロモンをたどって、さらに三匹のアリがエサを持ち帰ったとしましょう。これで全体の得の総和はさらにプラスされます。そして三匹のアリもフェロモンを発しながら帰るので、「北に行けば得だ」という情報の影響力が増していき、より多くのアリが北に向かうのです。
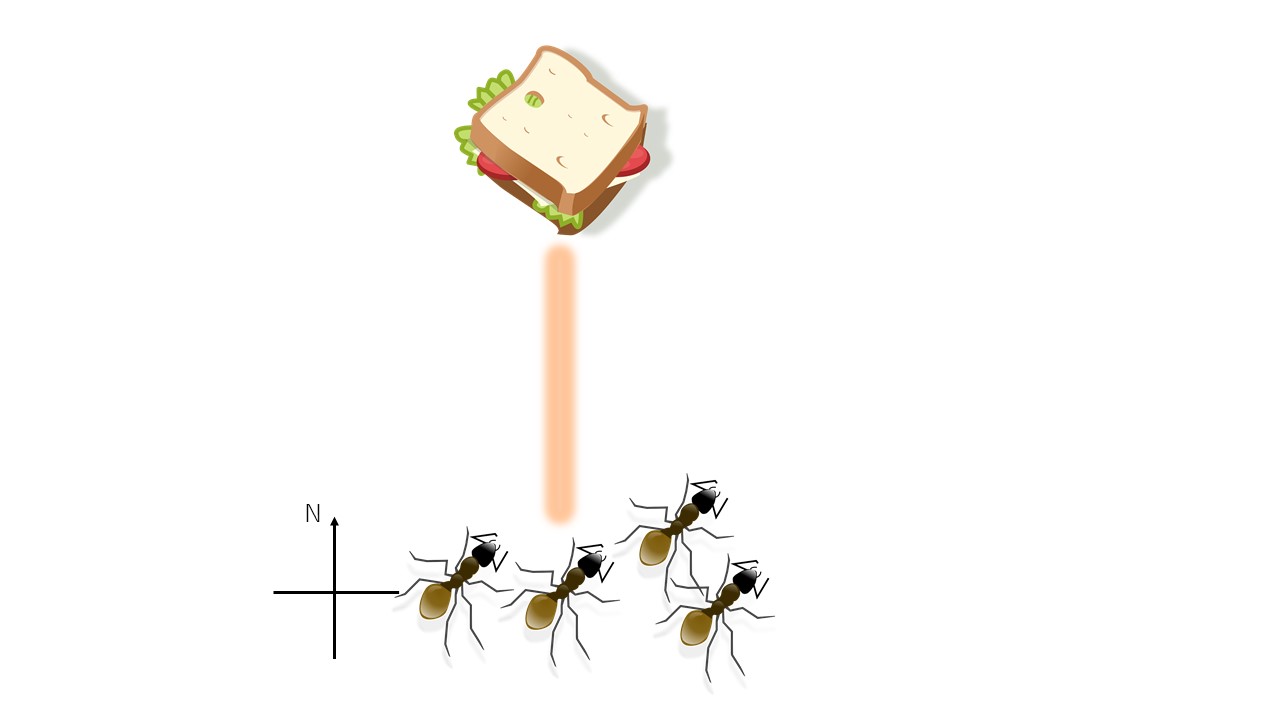
この例はまさに、エサを集めるという目標を達成するために集団が協調していくことを学ぶ過程と言っていいでしょう。
このような集団の協調行動はアリだけでなく、人間の活動においても重要な役割を果たしてきました。集団を作り、分業を行うことで生産性を向上させてきた人間の歴史を鑑みると、協調行動の習得は知的存在にとって大きな強みになると言えます。人工知能にとっても同じことでしょう。
ゲームでこのような協調行動の実践を学習する人工知能に関しては、アリババドットコムが興味深い成果を上げています。
Starcraft IIの前作にあたるStarcraftにおいて、人工知能が制御する各ユニットからの情報共有と行動決定にBiCNetというネットワーク技術を使うことで、人間のプレーヤーが駆使するレベルの集団戦法を学習させることに成功したのです。
動画内の説明は最小限ですが、ユニット同士ぶつからないよう移動させるという操作のセオリーのほか、複数ユニットでの一撃離脱戦法やオトリ戦法などを駆使する様子が見られます。学習は人間が関与せず、人工知能がトライアンドエラーを通じて行ったのというのですから驚きですね。
人工知能とゲームというトピックでは、人工知能か人間かという優位性の話題に向かいがちです。しかし、不完全情報ゲームへの進出や協調性の学習という技術的挑戦に目を向けると、より広い展望が見えてきます。
人工知能がゲームをプレイするというのは、単なる人間の勝ち負けという話にとどまりません。
困難な状況での意思決定、またチームワークの学習というステップは、現実世界の問題解決に対応できる人工知能、そして汎用人工知能開発のために重要となるのです。
一見実用性とはほど遠いゲームという舞台で、人工知能のブレークスルーが起きつつあると言えるでしょう。