Googleの人工知能がプロの棋士に勝ったというニュースが日本中を駆け巡りました。あまり詳しくない人にとっては何が凄いのか分からないニュースですが、将棋・チェス・囲碁の中で最も手数が多いのが囲碁であり、人工知能がプロに勝てない最後のボードゲームとも言われていたのです。
手数の多さが戦いの難しさに必ずしも直結するわけではありませんが、今までの人工知能は総当り式や得点方式でモノを考えて次の手を考えていたため、普通の対戦の時間内で囲碁の棋士に勝つのはまだまだ先だと考えられていました。しかし、ディープラーニングの登場で「手数の多さ」は人工知能の障害になったのです。一体、ディープラーニングを活用した人工知能はどのようにして囲碁や将棋を打つのでしょうか?
関連記事:
・深層学習(ディープラーニング)を素人向けに解説(前編)
・深層学習(ディープラーニング)を素人向けに解説(後編)
今までの人工知能の考え方

今までの人工知能の考え方は大きく分けて二つです。
一つは、「総当り方式で最も良い手を考える」方式で、二つ目は「ポイント方式で点数が高くなる手を考える」方式でした。
簡単に説明すると、総当り式は「こっちに指したらこうなるから、そうしたらこうなって・・・」という仮定のケースを無数に考えていき、その中から勝てる一手を打つというやり方です。
詰将棋なら良いですが、将棋や囲碁では選択肢が無数にある中で一つ一つ検証していくので時間がかかりますし、全てを計算することは出来ません。特に序盤では難しいでしょう。そこで点数式の出番です。
点数式は、強い駒を取ったら何点、敵陣に入ったら何点、有利な陣形を作れた何点など点数を設定し、より点数が高くなる手を打つというやり方です。囲碁であれば、相手の駒の位置や碁盤の形状から点数を設定して良い手を模索します。
人工知能はこれらの考え方を組み合わせて囲碁や将棋を打ちます。
要するに、終盤や小さな局面では手数が限られる場合には総当り式で十数手先を読み切り、序盤や中盤で手数が多い時には点数式でコツコツ点数を積み上げていくというやり方で人工知能は囲碁や将棋を打っているということです。
もちろん人工知能によって方式は様々で、全く異なるやり方をしているものもあります。それでも、基本的な考え方はこの二つになるでしょう。
素人が相手ならこれでも勝てますが、プロの棋士はそんなシンプルな考え方はしていません。経験と勘と読みを駆使して良い手を探し、人工知能にとっては点数が低いと思われる手も、「数十手先には点数が高くなる」ような手として打ってきます。そして、こうしたその場では良し悪しの分からない手が最終的には妙手となって、戦局を分けることになるのです。
総当りも点数式も考え方としては悪くありません。しかし、人工知能の囲碁や将棋は言わばマニュアルどおりの戦い方に過ぎず、そのようなやり方では妙手が生まれず、妙手を作れるプロ棋士に負けてしまいます。
いわば、妙手を生む能力が人工知能に欠けていたと言っても良いでしょう。
ディープラーニング式の人工知能の考え方
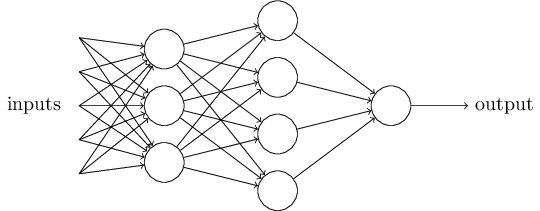
2016年現在、企業や大学が作ったディープラーニング式の人工知能が多数存在していますが、これは特定の人工知能の考え方について述べたものではありません。ディープラーニングの手法をベースに作られた人工知能を人に例えた場合、囲碁や将棋を指す時にどんな風に考えているのかというイメージだと考えて下さい。
まず、ディープラーニング式の人工知能がやることは、人間と同じように無数の棋譜を見て実際に指して見ることです。もちろん、ルールについては最初に人間が学ばせますが、どんな風に駒を打てば勝てるのかという部分は機械任せになるでしょう。
従来の人工知能であれば、その学習内容に基づいてシチュエーション毎にデータベース化して点数をつけていたかもしれません。しかし、ディープラーニングは人間のニューロンを模したパーセプトロンという小さな思考装置を集めて作った、言わば合議制の人工知能のようなものです。
また、詳しくは別の記事を読んでもらうとして、ディープラーニング式の人工知能は細々と全ての手を総当り式で考えたり、予め人が設定した点数に合わせて判断する事もありません。
役割分担された無数の小規模な思考装置が、与えられた役割を淡々とこなしながら、最終的な決断をする思考装置に判断を委ねるような仕組みになっています。言ってみれば、無数の部署から集められた情報・要望・施策から社長が最終判断をする人工知能と言っても良いでしょう。
ディープラーニングではこれだけでは終わりません。この小規模な思考装置(部署)同士の繋がりがディープラーニングのキモです。
人工知能は棋譜や実戦を通して部署間の発言力を変え、状況に合わせて優先的に意見を聞く部署を変化させます。さらに、必要性を感じたら新しい役割をこなす部署を作ることができるのです。また、この部署同士の繋がりも少しずつ変えていき、状況に応じて全く別のルートで情報伝達や指示が行われるようになっています。
将棋で言えば各駒毎に部署があるはずですし、相手の戦法を予測する部署や既に打った手の良し悪しを分析する部署もあるでしょう。また、手数の多い囲碁では局面毎に部署があり、大きな局面を見る部署や攻める局面と守る局面を決める部署もあるはずです。
本格的に棋士に挑むような人工知能であればさらに役割が小さく分けられ、何万と部署があるかもしれません。
この構図が人間の脳と似ていて、上述の部署に当たるニューロンは細胞同士の繋がりや構造が一つ一つ違います。これと同じことをディープラーニング式の人工知能はやっているのです。
この部署の構造をしっかりと作りこむことで、一つ一つの状況判断がより良くなっていきます。
人間の思いつかないような手を打つ
人間と同じような構造を人工知能の中に作ったからと言って人間のような手を打つわけではありません。人工知能の学習過程や環境は人間とは大きく異なっていて、戦法や場面ごとの優先順位は人間とは大きく異なるものになります。
人間のような常識は通用しませんし、定石や感情にも左右されません。
さらに、ディープラーニング式の人工知能は経験から学んで思考回路を作っているので、読みきったわけでもなく、その局面の点数をとるためでもなく、ある意味で経験的に勝てそうだという「勘に近い」手をうちます。
人工知能としては、今までの経験から作った部署の判断に基づいて次の手を選ぶというだけで、「百手先に絶対良くなる」とか「最終的に勝つ」という確信があって次の手を打つわけではありません。
これに関しては人間も同じでしょう。常に「百手先を正確に読んで打つ」なんてしませんし、終盤でも無ければ「勝てる確信があって打つ」なんてことはしません。殆どの手が経験やある意味「勘に近い予測」に基づいて次の手を打っています。
「どうしてこの手が良いと思った?」と聞いても、「この辺の状況が良くなると思って」ぐらいが関の山でしょう。
ディープラーニングの人工知能も同じで、「この辺の状況を分析した部署の発言がこの場面では優先されるから」みたいな答えが返ってくるかもしれません。
そして、勘は勘でも人間と全く違う思考回路が出した勘です。その答えは人間の勘とは全く違ったものになるのは当然でしょう。
ディープラーニングによって人間と同じような土俵に立つことが出来た人工知能が、今までのように「手数の多さ」に悩むことはありません。
その一方で、数百手先を読みきっているわけではないという点では人間と同じです。
つまり、今のところは「人間が絶対に勝てない相手」ではないのです。
いつの日か、人工知能の棋士を良きライバルとして切磋琢磨していく人間の棋士の姿が見られるかもしれません。
PR:人工知能をまとめて解説!




